Who this is for
The Crunchbase B2B Lead Discovery Pipeline is designed for sales teams, B2B marketers, business analysts, and data operations teams who need a reliable way to extract, structure, and summarize company information from Crunchbase to fuel lead generation and market intelligence.
This workflow is ideal for:
-
Sales Development Reps (SDRs) – Needing structured leads from Crunchbase
-
Marketing Analysts – Generating segmented outreach lists
-
Growth Teams – Identifying trending B2B startups
-
RevOps Teams – Automating company research pipelines
-
Data Teams – Consolidating insights into Google Sheets for dashboards
What problem is this workflow solving?
Manual extraction of company data from Crunchbase is time-consuming, inconsistent, and often lacks the contextual summary required for sales enablement or growth targeting.
This workflow automates the extraction, transformation, summarization, and delivery of Crunchbase company data into structured formats, making it instantly usable for B2B targeting and analysis.
It solves:
-
The difficulty of scaling lead discovery from Crunchbase
-
The need to summarize raw textual content for quick insights
-
The lack of integration between web scraping, LLM processing, and storage
What this workflow does
-
Markdown to Textual Data Extractor: Takes raw scraped markdown from Crunchbase and converts it into readable plain text using a basic LLM chain
-
Structured Data Extraction: Applies a parsing model (OpenAI) to extract structured fields such as company name, funding rounds, industry tags, location, and founding year
-
Summarization Chain: Generates an executive summary from the raw Crunchbase text using a summarization prompt template
-
Send to Google Sheets: Adds the structured data and summary into a Google Sheet for team access and further processing
-
Persist to Disk: Saves both raw and structured data files locally for archiving or further use
-
Webhook Notification: Sends a structured payload to a webhook endpoint (e.g., Slack, CRM, internal tools) with lead insights
Pre-conditions
- You need to have a Bright Data account and do the necessary setup as mentioned in the “Setup” section below.
- You need to have an OpenAI Account.
Setup
- Sign up at Bright Data.
- Navigate to Proxies & Scraping and create a new Web Unlocker zone by selecting Web Unlocker API under Scraping Solutions.
- In n8n, configure the Header Auth account under Credentials (Generic Auth Type: Header Authentication).
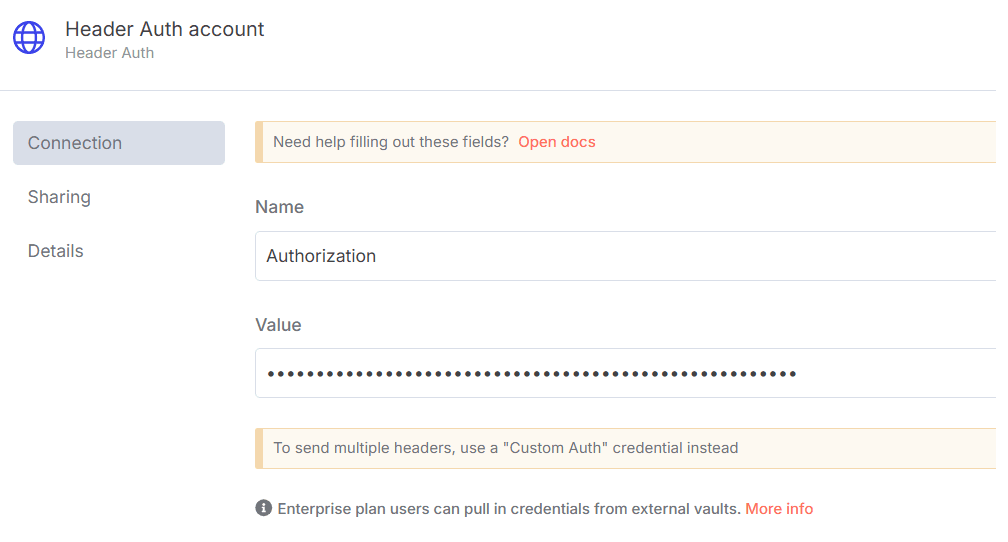
The Value field should be set with the
Bearer XXXXXXXXXXXXXX. The XXXXXXXXXXXXXX should be replaced by the Web Unlocker Token. - In n8n, Configure the Google Sheet Credentials with your own account. Follow this documentation – Set Google Sheet Credential
- In n8n, configure the OpenAi account credentials.
- Ensure the URL and Bright Data zone name are correctly set in the Set URL, Filename and Bright Data Zone node.
- Set the desired local path in the Write a file to disk node to save the responses.
How to customize this workflow to your needs
LLM Prompt Customization :
-
Modify the extraction prompt to include additional fields like revenue, social links, leadership team
-
Adjust summarization tone (e.g., executive summary, sales-focused snapshot or marketing digest)
File Persistence
- Store raw markdown, extracted JSON, and summary text separately for audit/debug
Webhook Notification
-
Connect to CRM (e.g., HubSpot, Salesforce) via webhook to automatically create leads
-
Send Slack notifications to alert sales reps when a new high-potential company is discovered